
盈易点 向人类再进一步|MIT×UMich探索可以理解物体空间关系的人工智能
本文转自雷锋网盈易点,如需转载请至雷锋网官网申请授权。
人类在描述场景时,经常描述物体之间的空间关系。生物视觉识别涉及自上而下通路和自下而上通路的交互,而深度神经网络只模拟了第二种通路。自上而下的视觉通路涉及生物视觉感知的全局性、拓扑性、多解性等特点,尤其是理解图像时会面临数学上的无穷解问题。而这些特点或许就是深度神经网络下一步的改进方向。
“视觉场景理解包括检测和识别物体,推理被检测物体之间的视觉关系以及使用语句描述图像区域。”依据《我们赖以生存的隐喻》的观点,物体关系相比于语义关系是更加基本的,因为语义关系背后都包含着物体关系的假设。
[[442261]]
就如下图中,两只猫猫在「互殴」,另一只猫猫在旁边不嫌事大地看热闹。通过这个例子,人类可以非常清晰直接地观察并捕捉到猫咪的位置、行为和关联。但许多深度学习模型却无法以相同的方式理解复杂实况,捕获全部信息并进行解析,因为它们不明白单个物体之间的「纠缠」关系。
那么问题来了,如果「捋不清」这些关系,像被设计用于厨房的机器人就很难执行「拿起菜板左边的柜子下面的炉灶上的铁锅炖大鹅」此类指令。
为了让机器人能够精准完成这些任务,来自麻省理工学院的Shuang Li、Yilun Du和伊利诺伊大学香槟分校的Nan Liu等人合作提出一款可以理解场景中物体之间空间关系的模型。该模型具有很好的泛化能力,能够通过组合多个物体的空间关系从而生成或者编辑复杂的图片。论文已作为Spotlight展示被NeurIPS 2021接收。

论文链接:https://arxiv.org/abs/2111.09297
总的来说,研究主要有三个主要贡献:
1. 提出了一个框架来分解和组合物体之间的关系,该框架能够生成和编辑图像根据通过组合物体之间空间关系描述,并且明显优于基线方法。
2. 能够推断出潜在物体之间的场景描述,并能够很好的理解物体之间的语义等效。语义等效是同样的场景但是不同的表述方式,例如苹果在香蕉左边和香蕉在苹果右边。
3. 最重要的这个方法通过组合物体关系的描述可以推广到以前未见过的更复杂关系描述中。
这种泛化可以应用于工业机器人执行复杂多步骤的操纵任务,比如在仓库中堆放物品或组装电器。让机器能进一步“仿生”人类从环境中学习、互动,并且通过不断学习分解,组合从而很快适应新的环境和学习新的任务。
共同一作Yilun Du说道:“当我们看到一张桌子时,不会用空间坐标系的XYZ三轴来表达物体位置, 因为人类大脑不是这样工作的。我们对周围环境的洞悉是基于物体之间的关系。通过构建能够理解物体关系的系统,更有效地操纵机械从而改变周围场景。”
单次单个关系
研究人员所提框架的亮点就在于,「它能以人类的方式“解读”场景中物体之间的关系」。
比如输入一段文本——木桌在蓝色沙发的右侧,木桌在木柜的前面。
系统首先将句子拆分为「木桌在蓝色沙发的右侧」和「木桌在木柜的前面」两部分,再逐一描述单独部分之间的空间关系,然后对每个关系概率分布建模,通过优化过程将这些分离的“结构”汇合,最终生成一个完整、准确的场景图像。

基于能量的模型(Energy-Based Model)
研究人员使用机器学习中「基于能量的模型」编码每一对物体直接的空间关系,然后像乐高积木一样将它们组合起来从而描述整个场景。
共同一作Shuang Li解释道:“系统通过重新组合物体之间的描述,从而产生很好泛化能力,可以生成或者编辑以前没有见过的场景。”

Yilun Du也表示:“其他系统是从整体上考虑场景中物体之间的关系,再根据文本描述中一次性生成场景图像。一旦包含更复杂的场景描述时,这些模型就无法真正的理解并且生产想要的场景图像。我们将这些单独的、较小的模型集成起来,实现对更多的关系进行建模,从而可以生产新颖的组合。
这个模型也可以逆向操作。给定一张图像和不同的描述文本,它能准确找到场景结构中与物体关系相匹配的描述文本。
理解复杂场景
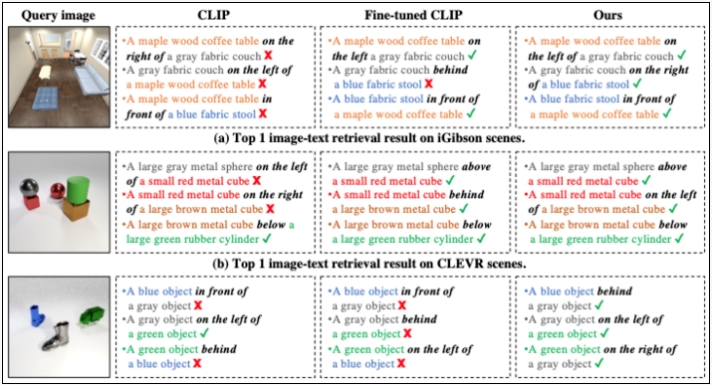
每种情况下,Nan Liu等人提出的模型都优于基线。
“我们的模型在训练过程中只见过一个物体关系描述,但是在测试中,当物体关系描述增加到两个、三个甚至四个的时候,我们的模型依然效果良好,其他机器学习方法则失败了。”
如图所示,图像编辑(Image Editing) 列出了不同方法在 CLEVR 和 iGibson 数据集上的分类结果。文中方法都大大优于基线—— StyleGAN2和StyleGAN2 (CLIP)。在 2R 和 3R 测试子集上的模型亦有优秀表现,所提方法对训练分布之外的关系场景描述具有良好的泛化能力。
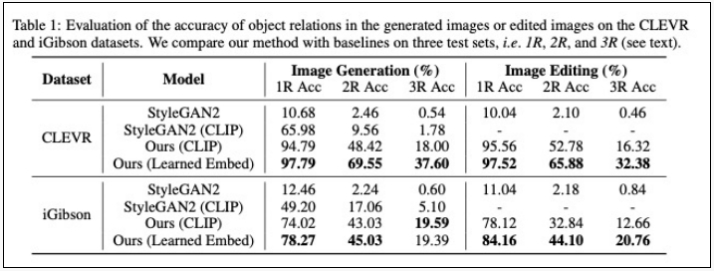
研究人员还请实验参与者评估生成图像和场景描述的匹配度。在描述包含三个物体关系的最复杂示例中,91% 的人认为该模型比其他基线的性能更好。
在模型代码网页上Interactive Demo的展示中,可以清晰看到新模型在多层物体位置中依然可以按照指令准确生成我们想要的图像。
OpenAI训练的神经网络模型「DALL·E」,也是可以根据文本标题为自然语言的各种概念创建图像。DALL·E 虽然可以很好的理解物体,但是不能够准确的理解物体之间的关系。
可以说Nan Liu等人提出的新模型鲁棒性十分优越,特别是在处理从未遇到的场景描述时,其他算法只能望其项背。
虽然早期实验效果甚佳,但研究人员希望模型能够进一步在更复杂的真实世界场景中(比如具有嘈杂的背景和相互阻挡的物体时)执行任务。更进一步让机器人能够通过视频推断物体空间关系,然后应用这些知识来和周边环境中的物体交互。”
捷克技术大学捷克信息学、机器人和控制论研究所的杰出研究员 Josef Sivic 说:“开发出可以理解事物关系并且通过不断组合认识新的事物是计算机视觉领域至关重要的开放问题之一。他们的实验结果着实令人惊叹。”
作者介绍
[[442263]]
Nan Liu, 伊利诺伊大学厄巴纳香槟分校硕士。2021 年毕业于密歇根大学安娜堡分校,获得计算机科学学士学位。目前从事研究计算机视觉和机器学习。
[[442264]]
Shuang Li, MIT CSAIL博士,师从Antonio Torralba盈易点。主要研究使用语言作为交流和计算工具以及构建可以持续学习并与周围世界互动的智能体。
[[442265]]
Yilun Du,MIT CSAIL博士生,受 Leslie Kaelbling 教授、Tomas Lozano-Perez 教授和 Josh Tenenbaum 教授指导。他对构建可以像人类一样感知理解世界的智能体和对构建模块化系统感兴趣。曾在国际生物学奥林匹克竞赛中获得了金牌。
[[442266]]
Joshua B. Tenenbaum,MIT脑认知科学系教授、CSAIL研究员。1993 年获得耶鲁大学物理学学士学位,1999 年获得麻省理工学院博士学位。Tenenbaum因对数学心理学和贝叶斯认知科学的贡献而闻名,他是最早开发并将概率和统计建模应用于人类学习、推理和感知研究的人之一。2018 年,R&D 杂志将 Tenenbaum 评为“年度创新者”。麦克阿瑟基金会于 2019 年授予他麦克阿瑟研究员称号。
[[442267]]
Antonio Torralba,MIT电气工程与计算机科学系 (EECS) 人工智能与决策系主任、CSAIL的首席研究员、MIT-IBM Watson AI Lab负责人、2021 AAAI Fellow。1994年获得西班牙电信BCN的电信工程学位,并于2000年获得法国格勒诺布尔国立理工学院的信号,图像和语音处理博士学位。他是“计算机视觉国际期刊”的副主编,并在2015年担任计算机视觉和模式识别会议的计划主席。2008年国家科学基金会职业奖,2009年IEEE计算机视觉和模式识别会议上获得最佳学生论文奖,2010年获JK国际模式识别协会颁发的Aggarwal奖。2017年Frank Quick Faculty研究创新奖学金和Louis D. Smullin优秀教学奖。
热点资讯
- 股票配资行情 稳外贸政策再加码 加大跨境金融支持力度
- 配资杠杆开户 前三季度主要指标均实现增长—— 交通运输运行平稳折射经济向好态势
- 配资网址 9月人民币全球支付占比为3.61%
- 线上配资开户 Spirit Air美股盘后涨超30%
- 股票配资服务 最糟糕开局!英国工党执政刚满100天 首相支持率已跌至新低
- 股票配资策略 央行同步降准降息加力稳增长 10月LPR料下降
- 配资代理 美诺转债:不向下修正转股价格
- 十倍杠杆炒股正规平台 2024外滩大会|蚂蚁集团财富事业群总裁王珺:AI+金融改变的是服务体验而非金
- 上海期货配资 ETF最前线 | 易方达中证芯片产业ETF(516350)下跌0.92%,苹果概念主题
- 炒股十倍杠杆 化债支撑城投债行情 “资产荒”下机构拉长久期